Reviving Sandstorm
By Ian Denhardt - 03 Feb 2020
Hi! I’m Ian Denhardt, a long-time Sandstorm user and community member. I have some exciting news to share. Let’s start by talking about some recent history.
It’s no secret that development on Sandstorm has been pretty sparse since Sandstorm-the-business shut down in 2017. The tone of that announcement was optimistic; while Sandstorm had failed as a business, as an open source project it had attracted an vibrant community, and there was hope that the project could continue to be successful outside of a for-profit setting.
Things didn’t go as smoothly as we’d hoped, however. While Sandstorm had had a healthy community of folks using it and building apps, there had been fewer contributions to Sandstorm itself from outside the company, and no one but Sandstorm employees had been doing major core development on a regular basis. Additionally, Kenton has had less time than he’d hoped to work on Sandstorm.
The project never quite died. It has continued to receive security and maintenance updates. Internationalization support was added, and several folks have stepped up to translate the UI into other languages. A few other features landed, and a few apps continued to see updates as well. But it would be more than fair to say that the project had stagnated, and while I and many others were still using it, it was clear that development wasn’t going anywhere fast.
That looks to be changing.
About two months ago, Lyre Calliope sent an email to the sandstorm-dev mailing list, starting a discussion on how to get the project moving again. Since then, I and others have been contributing code and documentation, and have had weekly “office hours” meetings. In spite of a full time job, moving across the country, and a new baby to take care of, Kenton has still managed find a bit of time to review and merge pull requests, and help plan. Here are some highlights of what’s been happening in terms of development:
- Jacob Weisz has done a ton of much-need work triaging our issue tracker, and has been working on some updates to vagrant-spk, looking to get a 1.0 release out soon.
- Adam Bliss updated our tooling for managing the docs website, to make review easier and so we can get updates out more quickly. As part of this, he’s updated the GitWeb app, and included support for static publishing. We’re calling the feature “GitWeb Pages”. He also fixed a long-standing bug in vagrant-spk, which will make the app development experience better.
- Lauri Ojansivu has been working on internationalizing the mass transfer feature that was added recently, and translating it into Finnish.
- I recently implemented support for apps scheduling background tasks, something that’s been a major pain point for developing certain types of applications. I’m working on a few follow-up tasks and related functionality, and put together a demo app that uses Sandstorm’s Powerbox API. To me, this is one of Sandstorm’s most exciting features, but having been implemented only shortly before the company shut down, it still has rough edges and the documentation is lacking. I plan to fix that.
As a community we’re once again very hopeful, and I personally am committed to spending what time I can making Sandstorm’s vision a reality. If you want to help, join us in the #sandstorm IRC channel on libera.chat, and sign up for the sandstorm-dev mailing list.
Sandstorm Oasis is Shutting Down
By Kenton Varda - 15 Sep 2019
On December 31st, 2019, Sandstorm’s paid hosting service, Sandstorm Oasis, will begin winding down.
- Only Oasis is affected. Other Sandstorm services, such as Sandcats.io, the app market, and automatic updates for self-hosted Sandstorm, will continue to operate.
- No new monthly payments will be accepted starting January 1st, 2020. Users will be able to finish out their last billing period paid in December and ending in January. Once your subscription ends, your apps will not be able to start up.
- Grain owners will continue to be able to download their data or transfer it to another Sandstorm server for at least another six months, until June 30, 2020. After that, data may become permanently unavailable.
It’s time to go Self-Hosted
If you’re an Oasis user, fear not! You can keep using Sandstorm on your own server, and you can easily transfer all your Oasis data to it.
Indeed, today, there’s almost no reason to prefer Oasis over a self-hosted Sandstorm server. Consider:
- A similarly-priced server on Digital Ocean running Sandstorm will load apps much faster than Oasis does, while giving you 5x the storage space.
- Users in Europe (of which Oasis has disproportionately many, even though we never really intended Oasis to be suitable for them) would be better-served by a European hosting provider, providing lower latency, and governed by European laws. Oasis is located in the United States.
- Oasis is currently operated by one person (me). I do my best, but should something happen to me, Oasis could disappear suddenly. In contrast, your self-hosted server will never disappear no matter what I do.
- Once Sandstorm is installed on your server, it’s almost entirely self-managing. Updates are installed automatically. TLS certificates are renewed automatically (with Sandcats.io). Modern VM hosts (like Digital Ocean) can perform automatic backups.
In order to make it extra-easy to transfer your data to a new server, I have added a new “Mass transfers” feature to Sandstorm. Find it by clicking the button at the top of your Grains list:
Then follow the on-screen directions to specify a destination server, review the list of grains to transfer, and then execute the transfer.
To recap:
Why shut down Oasis?
The story of the last few years
Sandstorm, as a company, mostly shut down two years ago. The company had run out of investor money while having achieved essentially no revenue, and no hard evidence that we’d ever achieve any. While Sandstorm was popular on Hacker News, that popularity never really converted into paying users. Meanwhile, in the market where we imagined we’d find real profits – enterprise software – we’d made no real progress whatsoever. In this state, we were unable to attract new investors, and we were unable to find a company to acquire the business.
The Sandstorm team was forced to look for new jobs. Most of us were hired by Cloudflare, though some chose to go elsewhere. Personally, I chose Cloudflare because I had always liked the technical culture I saw in their blog posts, and because I was interested in the project they wanted me to work on.
Originally, my plan had been to keep developing Sandstorm as an open source project. I felt – and still feel – that if only some rough edges could be smoothed out and some key missing features filled in, Sandstorm could really be a plausible replacement for the set of web services people use every day. I set a goal of getting myself off of Google services by replacing the key bits with Sandstorm apps – especially email. I thought that if I could really get that working, maybe we’d be in a position to relaunch the company.
I made some progress. On nights and weekends, I managed to clean up one of the hairiest rough edges of Sandstorm, fixing the identity system. I also rewrote the basics of how Sandstorm handles HTTP traffic, making it much faster and cleaner and removing JavaScript from a part of the system where it had no business being.
For a while, Oasis was costing far more to operate than it was taking in in revenue, with me making up the difference out-of-pocket. But, between the HTTP rewrite (which saved several machines), and discontinuing the Oasis free plan, I was able to bring things to the point where Oasis is mildly profitable, earning a few hundred dollars a month.
But, meanwhile, at my new job at Cloudflare, I am the lead engineer / architect of a project called Cloudflare Workers, a “serverless” platform that simultaneously deploys your code to 193 (and growing) locations around the world. Starting from scratch when I joined, I built a first prototype in a few months, had a public demo and beta customers shortly thereafter, and launched it to the world exactly (by coincidence!) a year after joining. Today, Cloudflare Workers handles something like a million times the traffic Sandstorm ever did. Meanwhile, the team has grown from just me to a literal bus-load of people. And we’re really just getting started.
As much as I love Sandstorm, it’s hard to come home from my successful day job to work on an unsuccessful side project. And so, I have been spending less and less time on Sandstorm. I still push updates every month to keep the dependencies fresh, but hadn’t worked on any new features in about a year and a half before adding mass transfers recently.
Meanwhile, without leadership, the community has mostly disbanded. The only app that gets regular updates anymore is Wekan, thanks to its maintainer Lauri “xet7” Ojansivu. Jake Weisz heroically continues to carry the Sandstorm flag, reviewing app submissions (mostly from Lauri), replying to questions and bug reports, and advocating Sandstorm around the internet. A couple others lurk on the mailing list and IRC. Most people have moved on.
Why not leave Oasis running?
Oasis is mildly profitable: it brings in about $1800 in revenue each month, while costing around $1400 each month between infrastructure, services, fees, and business upkeep (e.g. tax prep). Almost 200 people are paying for it and it appears most of them are in fact using it. As long as it isn’t losing money, why not let it be?
First, the obvious reason: It still takes time to operate. Once a month I have to spend my Saturday afternoon testing and pushing an update. Several times, changes in dependencies have broken things, requiring debugging time. In fact, Oasis’s cluster management and storage back-end (known as “Blackrock”) is still running a build from October 2018! For reasons I’ve been unable to determine, newer builds after that point start crashing under moderate load. I’m unable to reproduce such load in a test environment, so the only way to test potential fixes is to push out a full release, watch it fail, and roll it back. After several tries, I’ve mostly given up. Luckily, this component of Oasis has had no major changes and does not have any directly-exposed attack surface, so pinning the old version is mostly fine… but it’s a fragile position to be in.
On a related note, I am on call 24/7 for Oasis. It rarely breaks, but when it does, I have trouble fixing it in a timely fashion. For one example, in January, an unexplained Google Cloud hiccup forced me to transfer Oasis to another zone, which it wasn’t designed for (whoops, yeah, it’s not multi-homed, we never got that far). It was down for hours. Luckily it was a weekend and I was at home, or it could have been days. In another incident, I discovered that GMail had been routing all my monitoring alerts (and e-mail to support@, security@, contact@, etc.) directly to spam for months.
But, more important than the time burden on me is that I no longer feel good about charging money for this product. Almost all the app packages are from 2015-2016; many of those apps have had significant updates in their standalone versions since then which are missing on Sandstorm. Apps load super-slowly on Oasis. Many have significant missing features vs. their stand-alone versions, due to not having adapted to Sandstorm’s security model. And the Sandstorm UI itself remains woefully incomplete and janky. I constantly worry that most of the people paying for Oasis signed up by mistake and never noticed it on their credit card statements – that may sound far-fetched, but in fact I have had at least a few complaints from people who did just that (which I then refunded). I worry that it seems like we have European customers and I wonder if they realize Sandstorm is located in the US and may not comply with relevant European regulations. I feel embarrassed that people who haven’t read the blog assume the product is supported by full-time staff. Would Oasis still be profitable if it were only used by people who fully understand the state of the company? I’m not sure.
Finally, Oasis today provides almost no advantages over self-hosting. The price of virtual servers has come down to the point where self-hosting Sandstorm on an equivalently-priced server will give you a much better experience than Oasis can. Sandstorm was always supposed to be about owning your own server anyway. In fact, in retrospect, I think we never should have created Oasis, but should instead have focused entirely on self-hosting all along.
What’s next?
Sandstorm will continue to exist as an open source project. I personally plan to transfer my Oasis grains to a self-hosted server, and keep using it. I have to admit, building the mass transfer feature was kind of fun – I’d forgotten how little time it takes to build significant features in Meteor. And I’m still interested in self-hosting my email, if I can cobble together a decent UX. Maybe I’ll be inspired to build something on Sandstorm… we’ll see.
However, after the shutdown of Oasis, the project should be understood to be a hobby project, not a business. People should no longer rely on me, working in my spare time, to safeguard your data or keep it accessible.
Results of discontinuing the free plan
By Kenton Varda - 28 Oct 2018
Recently we made the tough decision to end Sandstorm Oasis’s free plan. This change has now been made and the dust is settled. (If you’re affected and are unsure how to export your data, see my previous blog post.)
Today, for the purpose of transparency, I wanted to show you the results of this change.
First, I’m happy to report that revenue increased more than I expected:
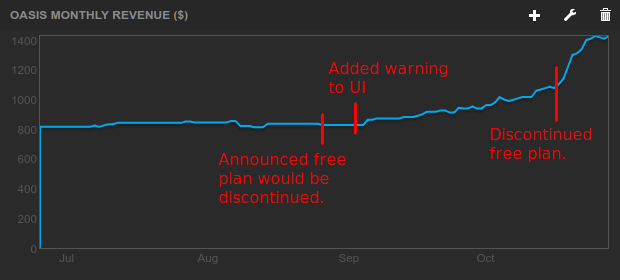
Timeline:
- August 27: MRR is $828. I announced decision to end the free plan on our blog and Twitter.
- September 2: MRR is still $828. I updated Oasis UI to add prominent warnings for free users.
- October 17: MRR has reached $1104. I flip the switch to turn off the free plan.
- October 28: MRR is now $1428.
Second, server resources were reduced. In particular, utilization of Oasis’s “worker” machines (where users’ apps actually run) dropped in half:

We previously had four worker VMs, each of which was a GCE “n1-highmem-2” machine costing $60.50 per month. We were able to cut two of those machines for a savings of $121.
Sandstorm currently runs 13 other VMs – six others to operate Oasis itself, three to run our web site and app market, two for Sandcats.io DNS, one for monitoring and one for metrics aggregation. It’s likely that we could further consolidate some of these, although these machines run smaller-sized instances with bespoke purposes meaning it will take a lot more work for comparatively smaller savings.
In August I estimated that the cost to continue operating Sandstorm (including servers and corporate maintenance) at about $1560 per month. With the server reduction, we’re now at $1439 per month – just barely above the $1428 in revenue. So, we went from a $700/month deficit ($8400/year) to break-even by making this change.
How to download your Oasis data
By Kenton Varda - 18 Oct 2018
We announced in August that Oasis’s free plan would be discontinued on October 14. As I explained then, we were forced to do this as Oasis costs $1500 per month to run, but was only earning $828 per month in revenue. I have been personally paying the remaining $700 every month to subsidize free users of the service, and I am unable to continue doing so. By limiting the service to only paying users, Oasis will be able to break even.
For the past month or so, the Sandstorm UI has featured a prominent message warning that the free plan was going away:
Unfortunately, we were unable to send an e-mail warning, as there are well over 100,000 free accounts on Oasis, the vast majority of which are abandoned. A mass e-mail would likely have landed us on spam blocklists (and rightly so, as we’d be annoying a lot of people).
I had hoped that the message in the UI was prominent enough that all active users would notice it. However, it appears that some people did not see the message, and now find themselves unexpectedly unable to open their apps. I’m very sorry for this!
Your data is still there
You can still download your data. To do so, open a grain and click the “download backup” button in the top bar, which looks like a down-arrow:
This will give you a ZIP file that contains all the data from the grain.
In some cases, you will be able to open this data easily. However, many apps store their data in custom formats that you may have difficulty opening. In these cases, it’s best to use the app itself to access the data, which means you need Sandstorm. One option is to install Sandstorm on your own server, but not everyone has a server available for this.
As a hack, another option is to use the Sandstorm Demo itself to get temporary access to your grains. The Sandstorm Demo gives you a temporary account which you can use to run any app on the Sandstorm app market, for free. The only catch is that your demo account will be deleted after one hour – but this should be enough time to upload your grain, open it, and copy out data. In the worst case, after your demo expires, you can always start another demo to extract more data.
To start a demo, open an incognito window or log out of Oasis, so that Oasis doesn’t know you have an account already. Then, visit demo.sandstorm.io or click the button on the Sandstorm.io home page:
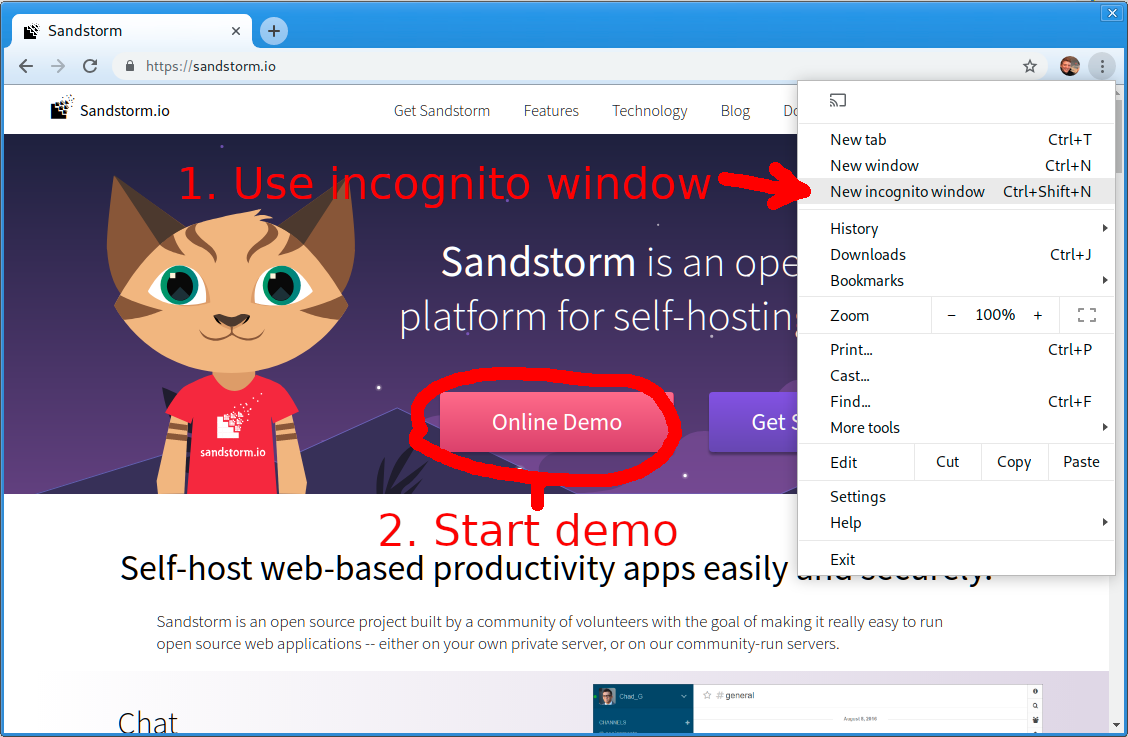
Once the demo has started, make sure to install the app that your grain was created with. Then, visit the “Grains” tab, click “Restore backup…”, and choose the backup zip that you downloaded before.
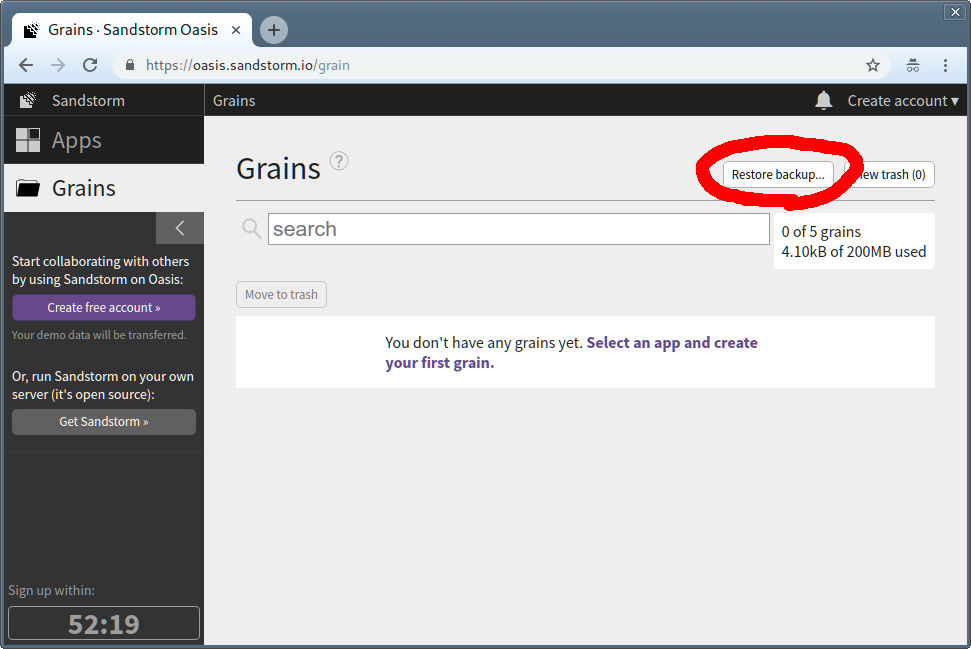
You now have a (temporary) functioning version of your grain.
Oasis free plan will be discontinued October 14
By Kenton Varda - 27 Aug 2018
Update: This change has now taken effect. Looking for help downloading your data from Oasis? See our latest blog post »
Starting October 14, 2018, Sandstorm Oasis’s “free” plan will be discontinued. Users will still be able to log in for free to access apps and grains owned by other, paying users, but free users will not be able to install their own apps nor create grains. Existing grains owned by free users will remain available for download via the “download backup” function, allowing you to transfer the data to a self-hosted Sandstorm server or manually extract it. However, the grains will no longer be able to start on Oasis unless you upgrade to a paid account.
Why do this?
Unfortunately, Oasis does not make enough money to support itself.
As of this writing, Oasis hosts 2642 monthly active users. This number is actually up in the last few months, despite Sandstorm having put no effort at all into user growth since we changed gears in early 2017.
However, only 88 of those users have a paid subscription, generating a total of $828 in monthly revenue. Unfortunately, the bare cost of operating Oasis currently comes to about $960 per month, mostly to pay for servers. Additionally, to keep Sandstorm the corporation in existence as a vehicle to operate Oasis costs around an additional $600 per month (for things like taxes, tax preparation, banking fees, etc.). Although these fees don’t technically go to keeping the service running, dissolving Sandstorm the company would almost certainly require shutting down Oasis, and so to keep Oasis running we must pay these fees.
All told, this means Oasis is running a deficit of $700 per month, which I personally pay out-of-pocket.
I do not want to shut down Oasis, because I know a lot of people depend on it and use it every day. But, it doesn’t make sense for me personally to pay for compute for every person who signs up. I need each user to pay their share.
What are the options for existing users?
If you currently have a free account with data on Sandstorm Oasis, you will need to do one of the following:
- Upgrade to a paid plan on Oasis.
- Switch to a self-hosted Sandstorm server. You can transfer your grains from Oasis to the new server by downloading a backup of each grain (down-arrow icon in the top bar when the grain is open) and uploading it to the new server. You won’t need to pay Sandstorm anything in this case, but by moving your grains off Oasis, you can help us shut down some servers to save money.
- Download your data and extract it manually. Sandstorm grain backups are simple zip files containing all of the data the app stored. The format is different from each app – it may be a JSON file, a SQLite database, a MongoDB, etc. You may need special tools and knowledge to extract the data, but it’s all there.
- Do nothing. Your data will remain intact and can be downloaded at any time. If you aren’t actively using your Oasis account, then you need not take action at this time.
FAQ
Have you considered a crowdfunding campaign?
Crowdfunding campaigns are harder than they look. Sandstorm ran one early in its life, successfully raising about $60,000. During that time, I had to spend every day for a month and a half going out and selling people on it. We lined up press articles. We had two paid employees pumping out apps. We got on Hacker News several times.
These days, I have a day job leading development of Cloudflare Workers and related projects. Workers is taking off quickly and there’s tons to do to make it better. Alas, I just don’t have time to coordinate another crowdfunding campaign for Sandstorm on the side.
Can I donate to Sandstorm via Patreon or something?
The best way to “donate” to Sandstorm is to sign up for a paid Oasis account. This is already set up, and the payment processing fees we pay to Stripe are much lower than what Patreon and the like would charge. All revenue from Oasis goes directly to paying for operation costs.
Will Oasis shut down eventually?
If Oasis remains non-profitable after this change, we’ll eventually have to shut it down. If it pays for itself, I’d like to keep it running, but I cannot make any guarantees. I will, of course, provide plenty of advance warning before shutting it down entirely.