HTTP proxy rewrite and other updates
By Kenton Varda - 19 Feb 2018
Development of Sandstorm continues! Despite now having a day job, I still spent a lot of my free time working on Sandstorm.
This past weekend, I deleted some of the oldest code in Sandstorm. This is the culmination of a few months of work: ever since early September, I have been working to transition the Sandstorm HTTP proxy from JavaScript to C++. This is the code which receives incoming HTTP requests, authenticates them, and forwards them to the appropriate grain (application instance). This low-level, performance-critical systems code.
Historically, HTTP proxying was a duty of Sandstorm’s “Shell” server. The Sandstorm Shell is Sandstorm’s user interface, an application written on Meteor and Node, and is responsible for most of Sandstorm’s business logic. Historically, the other major component of Sandstorm has been the “back end”, written in C++, responsible for running application containers and managing storage. HTTP proxying was done in the shell mostly because this was the most convenient place, building on Node.js’s HTTP library. However, performance (both CPU and memory usage) has been disappointing at best, and a debugging nightmare at worst.
Sandstorm now has a third component: the “Gateway”. This component receives all incoming HTTP traffic and forwards it to the appropriate destination. Requests related to Sandstorm’s UI are forwarded on as HTTP to the Shell over an internal Unix domain socket. Requests intended for apps are converted by the Gateway into Cap’n Proto requests and routed to the appropriate app. The Gateway also performs TLS termination (e.g. for users of our free TLS certificates under sandcats.io).
The Gateway is written in C++, using the KJ HTTP Library. KJ is the C++ toolkit library originally built as part of the Cap’n Proto project (itself a sub-project of Sandstorm), but which is beginning to take on a life of its own. KJ HTTP is a low-level yet easy-to-use HTTP client and server library, built on top of the KJ asynchronous framework (think Promises but in C++), all authored by yours truly. KJ HTTP is also used in the implementation of Cloudflare Workers (the project I lead in my day job), where it has already handled billions of requests.
We can see the performance improvement for Sandstorm Oasis, our hosting service which runs a special cluster-scalable version of Sandstorm. Oasis runs instances of the Sandstorm Shell on dedicated machines, with the ability to add more replicas as needed to handle traffic. Here’s the recent CPU usage history of one such replica:
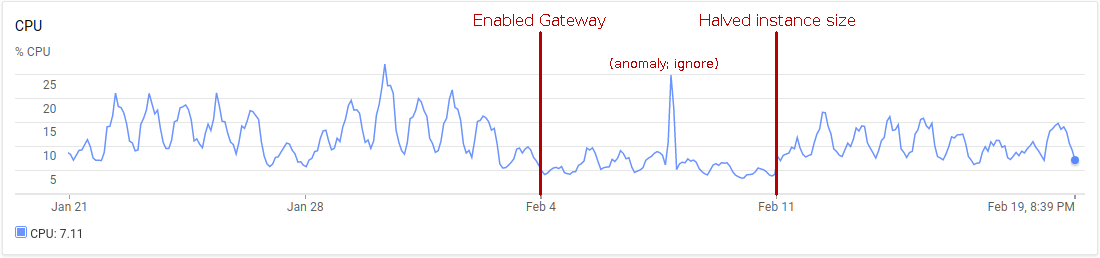
As you can see, introducing the gateway more than halved the CPU usage of the Sandstorm shell. Rather than reduce the number of replicas, I decided to cut the instance size in half. Either way, switching to the C++ Gateway saved money.
What about the Gateway itself? Where does it run, and how much CPU does it add? Well, historically, Oasis used an nginx instance for ingress, to provide TLS termination and load balancing. With the Gateway introduced, we were able to eliminate nginx from our stack: the Gateway is perfectly capable of handling TLS termination itself, and is able to implement session-affinity load-balancing much more effectively than nginx could due to the Gateway’s intimate knowledge of Sansdtorm internals. Thus, introducing the Gateway did not add any new VM instances to our system: it simply replaced the existing nginx instance. The Gateway’s CPU usage is negligible, using only a few percent of a CPU core. It appears to be on par with nginx, although when the numbers are this low it’s hard to really tell. I did ultimately decide to reduce the Gateway instance from a full CPU core to a half core to save some more cash.
These changes will roll out in full to self-hosted Sandstorm users on March 11 (the code is in git now, but I won’t have time to roll a release until then). Adventurous users can set EXPERIMENTAL_GATEWAY=true in their /opt/sandstorm/sandstorm.conf today, although note that this will give you the implementation as of the previous release two weeks ago, which still uses the old proxy for some things.
Other updates
Lauri Ojansivu has translated the Sandstorm UI to Finnish, and Benoit Renault and Thierry Pasquier have translated the Sandstorm UI to French. This means, along with English, Chinese, and Dutch, Sandstorm now supports five languages. Learn how to help translate Sandstorm here.
Next up
Here’s some things I want to work on next:
- Improving how app updates work. Today, you receive a notification when an app has been updated, and must explicitly accept the update. This unfortunately means that big Sandstorm servers with lots of users tend to get stuck storing every single historical version of every app forever, since there’s always someone who never updated after some version. I’d like to make updates fully automatic, but this requires some story for users who want to pin an older version, and some way to roll back to and older version in case of breakage.
- Integrating with Let’s Encrypt, once they support wildcard certificates. Hopefully, this will finally make it easy to run a secure Sandstorm server on your own domain. However, issuing a certificate requires completing a DNS challenge, and Sandstorm currently does not act as a DNS server. So, some manual intervention will likely still be required.
- Really supporting e-mail. Today, Sandstorm has some limited ability to accept e-mail, but can’t really act as a standalone e-mail server. I’d like to fix this, with the goal of migrating my own personal e-mail off of GMail and onto Sandstorm.
- Really supporting development workflows, centered around git. I want to be able to host a git repository, code review tools, a reasonable issue tracker, and a CI, all on Sandstorm, and all as separate apps.
- Making the top bar less ugly. People complain that Sandstorm’s UI is suffocating, especially the black bar across the top. However, Sandstorm’s security model requires that we have a place to hang trusted UI bits – such as the sharing dialog – that is separate from the app proper. Many apps, though, also have their own top bar with app-specific features, creating a double-top-bar effect. What I’d like to do instead is have a single top bar rendered by Sandstorm, but which can be customized by the app to include app-specific controls as well and to look visually consistent with the rest of the app.
- Many other things!
Want to get involved? Join the sandstorm-dev mailing list. and check out ways to contribute.
Sandstorm UI now available in Chinese, Dutch
By Kenton Varda - 28 Oct 2017
As of last week’s Sandstorm release (version 0.216), the Sandstorm UI is (mostly) now internationalized, meaning text has been moved out of the interface into separate translation tables.
This work was mostly done by Romulus Urakagi Tsai and Caasi Huang, supported by g0v.tw. Additionally, they contributed translation tables for Traditional Chinese, as well as a partial translation to Simplified Chinese (though the latter is still incomplete).
With i18n in place, other Sandstorm users immediately began work on other translations. In this week’s release (0.218), we’ve merged a Dutch translation by Michel van der Burg.
Would you like to contribute a Sandstorm translation? It’s easy – no programming required. Check out the contributing guide for instructions, and talk to us on the sandstorm-dev mailing list.
We're changing the way identities work
By Kenton Varda - 08 May 2017
UPDATE September 2, 2017: This change has been fully released and will roll out to all servers within the next 24 hours.
Over the next few weeks, I’ll be making a major change to the way Sandstorm handles user accounts and identities. My goal is to make things far less confusing.
Most Sandstorm users probably have no idea that these features exist, and so won’t notice the change. However, if you’ve linked multiple “identities” (multiple e-mail, Google, or GitHub accounts) to your Sandstorm account, you may want to read this.
History: The current system and why it was built this way
Way back in late 2015, we introduced the concept of “multiple identities” in Sandstorm. Ever since, a user account on a Sandstorm server has been able to have multiple identities attached to it, each with a different profile (name, picture, etc.). Once a user has multiple identities, they can choose which identity to act as when using apps. When users share with each other, they often do so “by identity”, meaning you choose the identity (not the account) with whom you want to share. It’s even possible for multiple accounts to share a common identity, in order to have multiple people “acting as” the same persona.
When we designed this system, we were attempting to solve several different problems at once:
-
We had long offered users the ability to log in with Google, GitHub, or e-mail. Sometimes, though, people wanted to attach multiple login mechanisms to the same account, e.g. both their Google and their GitHub account. This redundancy can protect people against one of these services being down, and would help avoid confusion when people can’t remember which login mechanism they used last time. We also anticipated that in the future, Sandstorm apps might want to talk to Google and GitHub APIs, and this access would be authenticated through the user’s connected accounts.
-
We wanted to ensure that the user ID seen by an app was a global identifier – meaning it would be the same even if the app was moved to a different Sandstorm server. This required that the ID be derived from the user’s credentials, e.g. a hash of their Google or GitHub user ID.
-
When users share with each other, we wanted them to be able to do so using well-known public identifiers, for additional security. Typically, Sandstorm users share with each other by creating and sending “secret links”; anyone who receives the link can get access. This is convenient, but sometimes you want some additional assurance that a link can’t be leaked. In that case, you might want to specify a specific GitHub username or Google account e-mail address with whom to share, and have Sandstorm guarantee that the receiver must authenticate as that identity to open the link.
-
We wanted people to be able to manage multiple “personas” with which they interact with other users within Sandstorm. We imagined that users may in fact want to prevent other users from discovering that these personas belonged to the same physical person. We imagined that this would in particular be useful to groups who fear harassment and abuse, and therefore choose to interact under a pseudonym.
-
We wanted multiple users to be able to collectively manage a shared persona, like a “brand account” on Twitter, while keeping independent Sandstorm accounts.
With all of these goals mashed together, we came up with a design: We would allow you to connect multiple credentials (e.g. Google, GitHub, e-mail, even multiple of each) to your account. Each connected credential became an “identity”, with its own profile (name, picture, and other details shown to users you collaborate with). Each identity could also be marked as being for authentication (in which case you could use it to log into your account) or not (in which case you couldn’t use it to log in, but you could use it as a persona and a sharing target). Non-login identities could also be shared between multiple accounts. Whenever you interacted with a grain, you would choose which identity you wanted to act as, which determined how collaborators saw you.
Why it didn’t work
In retrospect, it was a mistake to try to solve all of these problems at the same time, as they are all fundamentally different. By trying to link them together, we largely failed to solve any of them.
The idea that your Google and GitHub accounts each represented a different “identity” confused many users. Most people in fact only have one persona, and their accounts on various services represent that same persona. But if you attached both to your Sandstorm account, then Sandstorm would begin asking you to choose which identity you wished to act as – a question that made no sense to most people. Moreover, other people, when sharing with you, would begin to see multiple “copies” of you showing up in their contacts list – one for each credential. Often it was hard for people to tell what the difference was or which they should choose. Because of this confusion, the Sandstorm team has tended to steer people away from linking multiple identities in the first place. Obviously, this defeats the goals for which multi-identity was created.
Meanwhile, for people who actually wanted to manage multiple personas – pseudonyms, brand identities, etc. – we never managed to provide a good experience. It was very easy to accidentally use the wrong identity and reveal yourself. At the same time, the need to support this use case often exacerbated the confusion for users who only had one logical persona (as described in the previous paragraph). Without this design constraint, we could make a better UX for most people.
Finally, in practice this design didn’t really solve the ability to move grains between Sandstorm servers, because different Sandstorm servers may very well use totally different login mechanisms. Often, people want to transition grains from Oasis – where they used e-mail login – to a new self-hosted server – where they used LDAP or SAML login. Since the login mechanisms differed, user IDs didn’t match up anyway. To really solve this problem, we need something more dynamic.
What we’re doing instead
We are dropping support for multiple “personas”. Going forward, each Sandstorm account will have only one profile – one name, one profile picture, one entry in the sharing auto-complete list, etc. If you have multiple identities today, the profile from exactly one of those identities will become your account profile, and the other profiles will disappear. If you’re worried about which one Sandstorm will take, make sure to edit all your identities so that their profiles are the same.
What we call “identities” today will be renamed to “credentials”. A credential will no longer have its own profile, and you will no longer need to choose which credential you are acting as when accessing grains. Authentication-related features of credentials (for login, and for secure sharing) will remain mostly intact.
Users who rely on the ability to manage multiple personas today will need to transition to using multiple accounts instead. I suspect that there are vanishingly few such users, as most users never understood Sandstorm’s identity system in the first place. That said, if you are affected, I apologize. I would love it if you would get in contact with us to let us know about your specific needs, so that we can try to design a better experience for you. (For what it’s worth, I personally recommend using the multi-profile feature provided by various browsers to separate your personas into totally separate browser contexts with different window themes – this makes it much easier to prevent accidental leakage.)
Finally, we will be disassociating the user ID as seen by apps from the underlying user credentials. In the future, each grain will actually see a totally unique ID for each user. When a grain is transferred between servers, the owner will have the opportunity to remap users in arbitrary ways – though by default we’ll correlate based on verified e-mail address. This scheme has the additional benefit that because a particular user’s ID will be different in every grain they access, it will no longer be possible for apps to illicitly identify and correlate users by their IDs. Instead, they will have to use explicit APIs for this purpose, which can be carefully controlled for privacy.
Timeline
As of this post, these changes have not yet been implemented. We wanted to let people know of the changes in advance, in case anyone is relying on the current behavior. The next Sandstorm update will include code which detects users who might be affected and notifies them to read this blog post. The full change will probably take several weeks or maybe months to implement, as it is a huge change. We’ll update this post when it’s done.
The Sandstorm Team is joining Cloudflare
By Kenton Varda - 13 Mar 2017
Recently, we announced that Sandstorm is returning to its community roots, transitioning away from being a for-profit startup and towards being a community-effort, open source project. The Sandstorm team is committed to keep building Sandstorm in collaboration with our amazing community, and we will keep operating Sandstorm Oasis as a service. But, Sandstorm will no longer be our full-time jobs.
So, what will be?
Starting today, most of the Sandstorm team – including Jade and myself – now work for Cloudflare.
Sandstorm has actually been a user of Cloudflare since the beginning. Our web site and static parts of Oasis are served through them. I’ve long been a fan of Cloudflare’s focus on security. A few years back, I enjoyed their Heartbleed Challenge which proved conclusively that, yes, private keys can be leaked by Heartbleed. Although Cloudflare recently suffered from a widely-reported security incident, their response was impressively fast and transparent.
But a bigger reason I’m excited about joining Cloudflare is that they are big users – perhaps the biggest users – of Cap’n Proto, the serialization and RPC framework developed by Sandstorm. Cloudflare actually developed the Lua bindings for Cap’n Proto and has spoken publicly about using Cap’n Proto in their logging pipeline.
Sandstorm, for its part, remains an independent entity, and I won’t be working on it during my day job at Cloudflare. However, I will be working on Cap’n Proto. This should be good news for Cap’n Proto fans who have been disappointed by the lack of releases lately. Although Sandstorm uses Cap’n Proto extensively, in our scramble to build Sandstorm we tended to commit changes only to git master while neglecting to build (and test) formal releases. With a larger corporate backer, we can now afford to be more professional, doing more frequent releases, and putting effort into supporting more languages and platforms.
I will also be working on building some fascinating new infrastructure at Cloudflare. As a member of the edge platform team, I’ll be coming up with new ways to utilize Cloudflare’s machines located in over a hundred data centers around the world. Jade, meanwhile, will be working on building out Cloudflare’s community and developer advocacy program.
The Sandstorm community can expect to see me merging pull requests and pushing releases on weekends, with new releases at least every three weeks. There has been a flurry of activity lately around mobilizing community contributions. Join the discussion on the sandstorm-dev mailing list or on IRC (#sandstorm on Freenode)!
Sandstorm gets a security review
By Kenton Varda - 02 Mar 2017
Sandstorm recently underwent a security review by DevCore Inc., commissioned by Department of Cyber Security of Taiwan. The company has in the past found RCEs in big-name services like Uber and Facebook.
Although the full report is not public (and is not in English), Taiwan’s Digital Minister, Audrey Tang, tells us that overall DevCore feels Sandstorm has “excellent security design.”
As would be expected of any good security review, DevCore did find several issues. Last night we released build 0.203 to fix them. All servers should automatically update within 24 hours of the release (by midnight tonight, PST), but if you’d like to speed up the process (or if you have disabled automatic updates), you can SSH into your server now and type:
sudo sandstorm update
Vulnerabilities Discovered (and fixed)
1. Insufficient e-mail address validation
When logging in with an e-mail address, a user could enter an address like “foo@evil.com,bar@example.com”. In this case, login e-mails would be sent to both addresses, while Sandstorm would treat the user as if they were a member of the latter domain, “example.com”. Hence, an attacker could specify their real address as the first address and a fake address at a domain of their choice as the second, in order to appear to be a member of the domain. Servers that use Sandstorm’s organizational features (until recently only available as part of the now-defunct product “Sandstorm for Work”) can be configured to automatically promote members of a domain to full users, allowing them to install apps, create grains, and discover the identities of other members of the organization. Such users would not receive access to any other grains on the server, but an attacker could install their own apps that consume the server’s resources, including CPU, RAM, and disk. An attacker could also combine this vulnerability with one of the others below, all of which require full user status as a starting point.
The root cause of this bug is Sandstorm’s use of a library called Nodemailer to send e-mail. It turns out that Nodemailer “helpfully” interprets comma-separated lists of addresses as multiple addresses. This is true even if the string is already part of an array. For instance, say you pass the following array in the to field of a mail sent via Nodemailer:
[ "foo@example.com",
"bar@example.com,baz@example.com",
{ name: "Garply", address: "qux@example.com,corge@example.com" } ]
Surprisingly, this three-element array will send e-mail to five addresses – foo@, bar@, baz@, qux@, and corge@.
We did not anticipate this feature and assumed that Nodemailer would fail to send e-mail to an invalid address.
Severity: Moderate if Sandstorm is configured with an organization defined by e-mail domain. If you do not define an organization, or if you define it by LDAP, SAML, or G Suite domain, then we do not believe this bug can be meaningfully exploited.
Fix: Sandstorm now performs its own validation of addresses to ensure, among other things, that no separator characters are accepted and only one @-sign is allowed. Fixed in commit 37bd9a7.
2. Insufficient path validation when building ZIP backups
The owner of a Sandstorm grain can download a backup of the grain’s content in ZIP format. Sandstorm shells out to the zip utility to build this archive, but does so inside a sandbox designed to prevent exploitation of bugs in the utility.
Unfortunately, a combination of factors resulted in the possibility of a minor data leak:
- The list of files to include in the archive is passed to
zipon standard input, delimited by newlines. However, it is possible for a filename to contain a newline character. Sandstorm actually checked for this, but accidentally failed to perform the check in one code path triggered by the existence of an empty directory. - The zip sandbox carefully hid sensitive directories like
/var,/proc, and even/etc. However, after the zip sandbox was written, two new directories,/etc.hostand/run.host, which are aliases for the host system’s/etcand/run, were added. Unfortunately, the zip sandbox was not updated to hide these directories, hence they were visible to the zip program.
As a result of this, a user could create a grain containing an empty directory named /var/blah\n/etc.host/passwd, save a backup, and find the backup contained a copy of the host’s /etc/passwd file (which, despite its name, does not contain passwords, but does contain a list of local user accounts).
Severity: Low. An attacker who has full user status (permission to create grains) can read files located in the server’s /etc and /run directories that are set world-readable (or specifically readable to the Sandstorm service account). No other host system directories are exposed. Usually, any files under /etc that contain sensitive secrets would be hidden from all users except root, hence would not be readable by Sandstorm nor by the attacker.
Fix: We have fixed the validation of filenames so that newlines are never permitted, and we have enhanced the zip sandbox to use a whitelist of top-level directories rather than a blacklist. Fixed in commits 4ea8df7 and 6e8572e.
3. Server-side request forgery
Apps running on Sandstorm can make outgoing HTTP requests through a few mechanisms. Additionally, users can instruct Sandstorm to download an app package file from an arbitrary URL. Sandstorm did not attempt to prevent these requests from reaching localhost or private network destinations. Because of this, a full user of the Sandstorm server (but not a visitor) could probe the internal network on which the Sandstorm server was hosted, as well as services exposed to localhost on the server itself.
This is a problem if unprotected services are exposed to the Sandstorm server and you have invited users to your server who should not be trusted to access those services. Sandstorm itself does not expose any unprotected services to localhost, so some other service must be running locally to cause a problem. Only HTTP requests are possible.
Severity: High if unprotected HTTP services are visible to the Sandstorm server and you have invited users to your server who should not be trusted to access those services. Otherwise, low. Sandstorm itself does not expose any unprotected services to localhost, so some other service must be running locally to cause a problem. Only HTTP requests are possible.
Fix: Sandstorm now allows the server admin to configure an IP address blacklist. User-initiated requests will not be allowed from these addresses. By default, standard private network address ranges are blacklisted. Annoyingly, this “fix” is likely to break some servers who use private app indexes, but avoiding such breakage would mean leaving others vulnerable. Admins will need to update their blacklists accordingly. Fixed in commit 164997f.
4. Failure to mitigate Linux kernel CVE-2017-6074
(This was caught by Sandstorm core developer David Renshaw, not by DevCore, but is fixed in the same release.)
A recent Linux kernel bug could allow a malicious app to cause a kernel panic or perhaps break out of its sandbox. The bug is in Linux, but Sandstorm aims to protect against such bugs via seccomp. Historically, Sandstorm’s sandbox has been very successful at blocking Linux vulnerabilities before they are discovered. However, this one slipped through. On Sandstorm, the published PoC exploit for this bug only causes a kernel panic (not a sandbox breakout), but a developer with deep understanding of the bug and the Linux kernel might be able to create a successful attack in other ways.
Severity: High if you permit users you don’t trust to install apps on your server, or commonly install apps from untrustworthy sources, and you do not keep your kernel up-to-date.
Fix: Sandstorm’s seccomp filter has been updated to prohibit the creation of DCCP sockets. Fixed in commit 34749f9.
Conclusion
We are excited to have received such a thorough security review. Some of the problems discovered were very obscure and we’re impressed that DevCore was able to find them. We thank Audrey Tang and the Department of Cyber Security of Taiwan for commissioning this review.